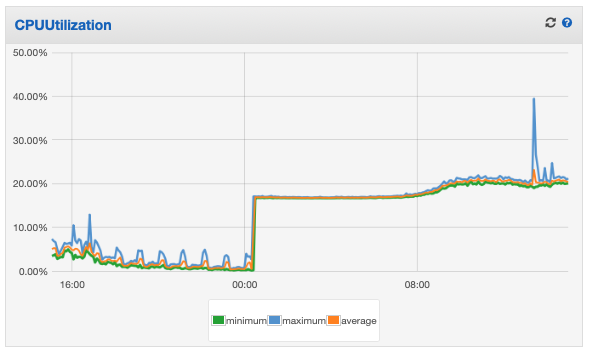
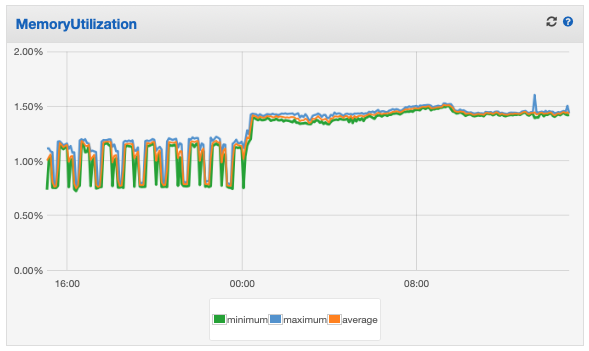
Some further info (dates & logs) that could give some clues (sorry for the long post)…
We started capturing descent logs in Cloud Watch for this on 13th Jan. At that point, all looks good:
2021-01-13T00:25:14.295+00:00 INFO [2021-01-13 00:25:14] 108 Scheduler: executing task Piwik\Plugins\CoreAdminHome\Tasks.purgeInvalidatedArchives...
2021-01-13T00:25:15.133+00:00 INFO [2021-01-13 00:25:15] 108 Found 14 invalidated archives safe to delete in matomo_archive_numeric_2021_01.
2021-01-13T00:25:15.223+00:00 DEBUG [2021-01-13 00:25:15] 108 Deleted 322 rows in matomo_archive_numeric_2021_01 and its associated blob table.
This ran fine (daily) until 27th Jan where we got this:
(PS - we have since increased the PHP memory limit)
2021-01-27T00:24:35.522+00:00 INFO [2021-01-27 00:24:35] 108 Scheduler: executing task Piwik\Plugins\CoreAdminHome\Tasks.purgeInvalidatedArchives...
2021-01-27T00:25:02.621+00:00 ERROR [2021-01-27 00:25:02] 108 Fatal error encountered: /var/www/html/libs/Zend/Db/Statement/Pdo.php(233): Allowed memory size of 134217728 bytes exhausted (tried to allocate 61440 bytes)
2021-01-27T00:25:02.621+00:00 on /var/www/html/libs/Zend/Db/Statement/Pdo.php(233)
…but ran OK again on 28th:
2021-01-28T00:13:53.018+00:00 INFO [2021-01-28 00:13:53] 108 Scheduler: executing task Piwik\Plugins\CoreAdminHome\Tasks.purgeInvalidatedArchives...
2021-01-28T00:14:34.463+00:00 INFO [2021-01-28 00:14:34] 108 Found 4337 invalidated archives safe to delete in matomo_archive_numeric_2021_01.
2021-01-28T00:14:43.125+00:00 DEBUG [2021-01-28 00:14:43] 108 Deleted 35129 rows in matomo_archive_numeric_2021_01 and its associated blob table.
It continued fine until the end of the month (completed OK on Jan 31st).
Then, on 1st Feb, we got another…
2021-02-01T00:04:32.372+00:00 INFO [2021-02-01 00:04:32] 108 Scheduler: executing task Piwik\Plugins\CoreAdminHome\Tasks.purgeInvalidatedArchives...
2021-02-01T00:05:51.254+00:00 ERROR [2021-02-01 00:05:51] 108 Fatal error encountered: /var/www/html/libs/Zend/Db/Statement/Pdo.php(233): Allowed memory size of 134217728 bytes exhausted (tried to allocate 131072 bytes)
2021-02-01T00:05:51.254+00:00 on /var/www/html/libs/Zend/Db/Statement/Pdo.php(233)
Then on 2nd:
2021-02-02T00:20:17.583+00:00 DEBUG [2021-02-02 00:20:17] 107 Executing tasks with priority 9:
2021-02-02T00:20:17.591+00:00 DEBUG [2021-02-02 00:20:17] 107 Task Piwik\Plugins\CoreAdminHome\Tasks.purgeInvalidatedArchives is scheduled to run again for 2021-02-03.
2021-02-02T00:20:17.591+00:00 INFO [2021-02-02 00:20:17] 107 Scheduler: executing task Piwik\Plugins\CoreAdminHome\Tasks.purgeInvalidatedArchives...
(and at that point the archiver locks-up entirely - no more errors logged and the CPU running 100%)
We’ve been digging into this more deeply this week and increased the PHP memory limit - but on the next run:
2021-02-05T17:22:12.452+00:00 DEBUG [2021-02-05 17:22:12] 107 Executing tasks with priority 9:
2021-02-05T17:22:12.458+00:00 DEBUG [2021-02-05 17:22:12] 107 Task Piwik\Plugins\CoreAdminHome\Tasks.purgeInvalidatedArchives is scheduled to run again for 2021-02-06.
2021-02-05T17:22:12.458+00:00 INFO [2021-02-05 17:22:12] 107 Scheduler: executing task Piwik\Plugins\CoreAdminHome\Tasks.purgeInvalidatedArchives...
(locked-up again at this point)
It’s still there, having been “running” for 36 hours (I’d left it in the hope it might finish whatever it’s doing - but I’m not convinced it will get any further).
Any ideas what might fix this?
I’d been wondering whether ./console core:purge-old-archive-data all might help?
If anyone has any thoughts or advice, would be much appreciated.
Many thanks.